BP神经网络的梯度公式推导(三层结构)
创始人
2024-04-10 03:21:19
0次
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com
目录
一. 推导目标
1.1 梯度公式目标
1.2 本文梯度公式目标
二. 网络表达式梳理
2.1 梳理三层BP神经网络的网络表达式
三. 三层BP神经网络梯度推导过程
3.1 简化推导目标
3.2 输出层权重的梯度推导
3.3 输出层阈值的梯度推导
3.4隐层权重的梯度推导
3.5 隐层阈值的梯度推导
四. 推导结果总结
4.1 三层BP神经网络梯度公式
BP神经网络的训练算法基本都涉及到梯度公式,
本文提供三层BP神经网络的梯度公式和推导过程
一. 推导目标
BP神经网络的梯度推导是个复杂活,
在推导之前 ,本节先把推导目标清晰化
1.1 梯度公式目标
训练算法很多,但各种训练算法一般都需要用到各个待求参数(w,b)在损失函数中的梯度,
因此求出w,b在损失函数中的梯度就成为了BP神经网络必不可少的一环,
求梯度公式,即求以下误差函数E对各个w,b的偏导:
代表网络对第m个样本第k个输出的预测值,w,b就隐含在
中
1.2 本文梯度公式目标
虽然梯度只是简单地求E对w,b的偏导,但E中包含网络的表达式f(x),就变得非常庞大,
求偏导就成了极度艰巨晦涩的苦力活,对多层结构通式的梯度推导稍为抽象,
本文不妨以最常用的三层结构作为具体例子入手,求出三层结构的梯度公式
即:输入层-隐层-输出层 (隐层传递函数为tansig,输出层传递函数为purelin)
虽然只是三层的BP神经网络,
但梯度公式的推导,仍然不仅是一个体力活,还是一个细致活,
且让我们细细一步一步慢慢来
二. 网络表达式梳理
在损失函数E中包括了网络表达式,在求梯度之前,
先将表达式的梳理清晰,有助于后面的推导
2.1 梳理三层BP神经网络的网络表达式
网络表达式的参考形式
隐层传递函数为tansig,输出层传递函数为purelin的三层BP神经网络,
有形如下式的数学表达式

网络表达式的通用矩阵形式
写成通用的矩阵形式为
这里的为矩阵,
和
为向量,
上标(o)和(h)分别代表输出层(out)和隐层(hide),

例如,2输入,4隐节点,2输出的BP神经网络可以图解如下:

三. 三层BP神经网络梯度推导过程
本节我们具体推导误差函数对每一个待求参数w,b的梯度
3.1 简化推导目标
由于E的表达式较为复杂,
不妨先将问题转化为"求单样本梯度"来简化推导表达式
对于任何一个需要求偏导的待求参数w,都有: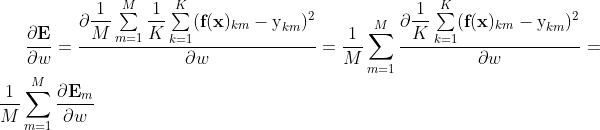
即损失函数的梯度,等于单个样本的损失函数的梯度之和(E对b的梯度也如此),
因此,我们先推导单个样本的梯度,最后再对单样本梯度求和即可。
现在问题简化为求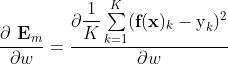
3.2 输出层权重的梯度推导
输出层权重梯度推导
输出层的权重为"输出个数*隐节点个数"的矩阵,
现推导任意一个权重wji (即连接第i个隐层与第j个输出的权重)的单样本梯度
如下:
事实上,只有第j个输出是关于
的函数,也即对于其它输出
因此,
上式即等于

继续求导是第j个输出的误差,简记为

是第j个隐节点的激活值,简记为
(A即Active)
上式即可写为
上述是单样本的梯度,
整体样本的梯度则应记为
M,K为样本个数、输出个数是第m个样本第j个输出的误差
是第m个样本第i个隐节点的激活值

3.3 输出层阈值的梯度推导
输出层阈值梯度推导
对于阈值(第j个输出节点的阈值)的推导与权重梯度的推导是类似的,
只是上述标蓝部分应改为
简记为![\dfrac{\partial \textbf{E}_m}{\partial b_\textbf{j}^{(o)}} =\dfrac{1}{K}* 2 *E_\textbf{j}]()
上述是单样本的梯度,
整体样本的梯度则应记为
M,K为样本个数、输出个数

3.4隐层权重的梯度推导
隐层的权重为"隐节点个数*输入个数"的矩阵,
现推导任意一个权重(即连接第i个输入与第j个隐节点的权重)的单样本梯度
如下:
只有第j个tansig是关于
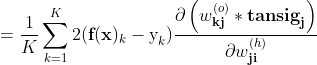
继续求导



又由
所以上式为:
简写为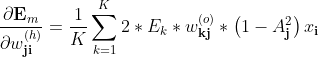

上述是单样本的梯度,对整体样本则有:
M,KM,K为样本个数、输出个数是第m个样本第k个输出的误差
是第m个样本第i个输入
3.5 隐层阈值的梯度推导
隐层阈值梯度推导
对于阈值b_\textbf{j}^{(h)} (第j个隐节点的阈值)的推导与隐层权重梯度的推导是类似的,
只是蓝色部分应改为
又由
所以上式为:
简写为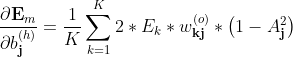
上述是单样本的梯度,对整体样本则有:
M,K为样本个数、输出个数
四. 推导结果总结
4.1 三层BP神经网络梯度公式
输出层梯度公式
输出层权重梯度:
输出层阈值梯度:
隐层梯度公式
隐层权重梯度:
隐层阈值梯度: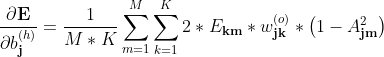
✍️符号说明
M,K为样本个数、输出个数
相关文章
《BP神经网络梯度推导》
《BP神经网络提取的数学表达式》
《一个BP的完整建模流程》
相关内容
热门资讯
特朗普再掀风波,威胁起诉美联储...
美东时间周一,“懂王”特朗普再次将矛头指向美联储,公开表示正考虑以“严重失职”为由,对现任美联储主席...
*ST熊猫收到中国证监会立案告...
雷达财经雷助吧出品 文|简白 编|深海 12月29日,*ST熊猫发布《关于收到中国证券监督管理委员会...
以法治之力助推政务服务提质增效...
河南日报客户端记者 马涛 杨伟 河南日报社全媒体记者 刘霄 2026年1月1日,《许昌市政务服务条例...
诉讼证据系AI生成,触碰法律红...
文丨默 达 图丨张宇晴 近日,湖北一地法院审理案件时,发现原告提交的照片中赫然带有“豆包AI生成”...
安永参与浙江省境外投资法律合规...
12月26日,由浙江省商务厅主办、浙江省境外投资企业协会承办、浙企出海综合服务港协办的浙江省境外投资...
经济日报:财政政策明年如何更加...
中央经济工作会议部署,2026年我国继续实施更加积极的财政政策。扩大财政支出盘子、优化政府债券工具组...
皮海洲:监事会撤销了,独立董事...
皮海洲 | 立方大家谈专栏作者 随着时间向2026年靠近,有越来越多的上市公司公布了撤销公司监事会的...
45岁家长放学护岗时晕倒送医后...
极目新闻记者 刘琴 12月29日下午,张家界永定区天门小学一位家长在放学护岗时晕倒,送医后死亡,当地...
男子去世现配偶、亲生女、继子和...
再婚家庭的遗产继承问题,往往争执不下牵连众多,常常让亲情与法律纠缠不清,比普通家庭更加复杂。近日,宣...
天亿马中标:鹤壁市社会治安综合...
证券之星消息,根据天眼查APP-财产线索数据整理,根据中国共产党鹤壁市委政法委员会12月28日发布的...